
奇迹暖暖小丑恶作剧怎么搭配 搭配攻略
|| 星星之火,可以燎原。2024 年 4 月 26 日,科大讯飞的星火大模型 V3.5 春季上新,一句话声音复刻功能让科技更有温度;推出星火智能体平台,助企业

|| 星星之火,可以燎原。
2024 年 4 月 26 日,科大讯飞的星火大模型 V3.5 春季上新,一句话声音复刻功能让科技更有温度;推出星火智能体平台,助企业解决大模型应用落地 " 最后一公里 " 难题;确定 6 月 27 日正式发布讯飞星火 V4.0……
这其中,讯飞星火成为业界*支持 " 长文本、长图文、长语音 " 的大模型,成功抓住用户高效准确知识获取的痛点,尤为引人瞩目。
相比之下,长文文字长度 " 全球* " 的攀比变得索然无趣。
时至今日,科大讯飞为什么要做长文本、长图文、长语音的大模型?长文本、长图文、长语音的大模型,到底成色几何?闯入大模型决赛圈,科大讯飞的底气何在?
" 长文本 " 竞争,迈入 2.0 时代
ChatGPT 横空出世,催生了 " 百模大战 "。
百家争鸣之下,行业也在思考大模型的价值,从尝鲜走向实用成为共同的诉求,于是乎应用落地成为大模型博弈的 " 主战场 "。
不过," 大厂们 " 的主要精力在 B 端,通过赋能产业的方式,实现共生共荣共赢。
与之对应是,C 端重视的程度有所不及,提效需求长期得不到彻底满足,以至于 " 修改 AI 生成文案的时间,不比从头想来的少 " 成为共鸣。
直到 " 长文本 " 出现,才有了微妙的变化。
毕竟,人工阅读长文本耗时按小时计算,但大模型耗时按秒计算,提效肉眼可见,C 端知识高效获取从梦想走向现实。
公开资料显示,GPT-4Turbo-128k 的文本范围约为 10 万汉字,Claude3200k 约为 16 万汉字,而以 Kimi 为首的国内大模型不断内卷,长文本处理能力从 20 万汉字一路攀升超千万汉字,上演了一出 " 军备竞赛 "。
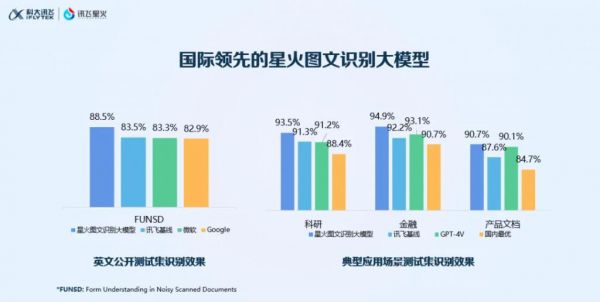
作为既懂 B 端又懂 C 端的公司,科大讯飞却有不同的看法。
科大讯飞分析发现,在知识获取和学习的过程中,广大用户能拿到的资料往往不仅是现成的长文本,还有随手可见的报刊书籍内容、各种研讨会的 PPT 内容,老师黑板上的板书、同学的笔记,以及各种会议录音、访谈,各种网上的发布会、培训教育视频等,如何把这些文本、图片、语音等都上传到讯飞星火中,则可以快速地获取全维度的知识。
通俗易懂地说,科大讯飞跳出长文本之争的固有思维,通过多模态进行降维打击,真正面向用户高效知识获取的多元场景,摆脱了 " 长文本 " 当下的内卷。
对此,科大讯飞董事长刘庆峰表示:" 我们从星火 APP 的应用看到,使用的*高峰不是周末,而是工作日,使用的*高峰时间是在工作日的上午 9:30 和下午的 3:30,也就是说绝大部分用户是由我们讯飞星火来解决和工作相关的问题的。"
七麦数据显示,讯飞星火 APP 在安卓端的下载量已经超过 9600 万次,在国内工具类通用大模型 APP 中排名*。
从可用走向爱用,从场景中找到刚需
以上可见,持续用技术进步解决真实刚需,是讯飞星火获得用户认可的关键所在,也契合科大讯飞大模型一直秉持的 " 解放生产力,释放想象力 " 宗旨。
事实上,科大讯飞的长文本、长图文、长语音大模型,堪称职场人的提效 " 神器 "。
一方面,长文本处理更专业。
虽然越来越多的大模型支持长文本处理,但含金量却并不相同,之所以如此与使用 RAG(检索增强)算法息息相关。
一名业内人士告诉锌刻度:" 所谓 RAG 算法,可以简单粗暴地理解为长文本拆分成多个短文本再进行处理,从而降低了技术门槛,拼长度很有优势,但捕捉上下文能力相对不足,进而降低了处理效率,并在精准性、连贯性、可靠性上处于劣势。"
上述业内人士进一步表示,RAG 算法满足可用标准,适合一些对知识准确度要求不高的工作场景,需要用户人工再检查一遍,而无损算法可以完整地捕捉上下文内容,从而理解长文本更准确,满足易用标准。
讯飞星火则更进一步,达到好用与爱用的标准。
讯飞星火通用长文本能力,包括长文档信息抽取、长文档知识问答、长文档总结、长文档文本生成等,总体已经接近 GPT-4 Turbo,而在各垂直领域的知识问答任务上,星火大模型长文本总体水平已经超过 GPT-4 Turbo。
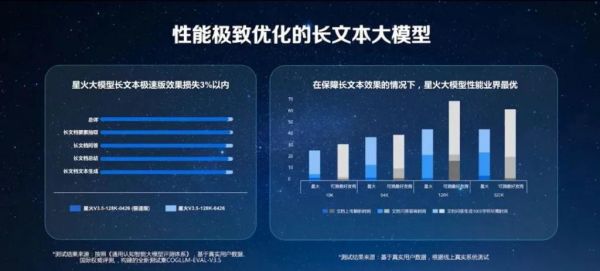
更为重要的是,借助稀疏剪枝技术与知识蒸馏技术,推出业界*优的 130 亿参数的大模型在效果损失仅 3% 以内的情况下,使得星火在文档上传解析处理、知识问答的首响时间以及文字生成方面都获得了极大的效率提升。
测试显示,在保障长文本效果的情况下,无论是 10K、64K、128K token,还是更长的文本上,星火大模型的性能都做到业界*优。
如此一来,即使潦草手写文字的识别也不在话下,而这曾是 Kimi 的痛点。
另外一方面,创新瞄准刚需。
作为后入者,单单更专业是不够的,还需要有独到之处才可以后来居上,科大讯飞从场景中找到刚需,再通过满足刚需达到创新的目的。
于是乎,长图文、长语音令讯飞星火占据了 " 人无我有 " 的竞争优势。
更为关键的是,长文本、长图文与长语音相互促进,应用场景得到极大的扩展,讯飞星火落地也顺势获得更大的增量场。
譬如,日常生活中经常碰到冗长的购房合同、保险合同等,看不懂、看不完、看不全成为一个长期的痛点,长文本与长图文叠加则可以对合同进行风险审核、合同比对、摘要总结等,迅速识别潜在风险漏洞,让合同处理更便捷、更高效、更准确。
再譬如,长文本叠加长语音,可以帮助提升实录转写的效率以及篇章梳理能力,让教师备课、学生复习更方便、更轻松、更省心。
另外,讯飞 AI 学习机是全球*认知大模型 AI 学习机,长图文与长语音叠加可以提升了 AI 学习机是的智能化辅学能力,赋予英语口语陪练、中英作文批改、数学互动辅学、百科自由问答、亲子教育助手等更强的互动性,增加孩子的学习兴趣,进一步释放孩子的创造力、启发力与想象力。
2023 年,受益于讯飞星火,讯飞 AI 学习机、讯飞智能办公本,讯飞智能录音笔、讯飞智能翻译机等 C 端硬件产品的 GMV 实现 84% 增长。
由此可见,长文本、长图文、长语音的 " 化学反应 ",解决了用户在全场景中更高效获取知识的刚需。
想象力变为生产力,算力底座是关键
不难看出,科大讯飞为大模型博弈指明了一个行业方向:避免无效的 " 内卷 ",回归技术创新的 " 主航道 ",则可以上演弯道超车的好戏。
毕竟,技术创新才是*大的生产力。
而要把想象力变为生产力,则离不开科大讯飞长期苦练基本功,夯实了大模型底座,如此才能跑得快、更跑得远。
简而言之,算力才是大模型的底座,是支撑长文本、长图文与长语音的重要保障。
巧的是,科大讯飞一直坚持做难而正确的事情:相较行业的 " 大玩家们 ",科大讯飞的资金并不突出,却持之以恒地加码算力,成为屈指可数拥有大模型底座的 AI 企业。
财报数据显示,科大讯飞 2023 年的研发费用为 38.39 亿元,同比增长 11.89%,而全年净利润也不过 6.57 亿元,研发费用是净利润的 5.84 倍," 该投的投,绝不手软,应投尽投,饱和投入 "。
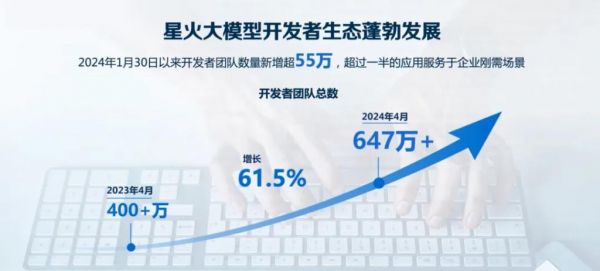
值得一提的是,科大讯飞的算力底座自主可控。
2023 年 10 月,科大讯飞与华为联合发布*支撑万亿参数大模型训练的万卡国产算力平台 " 飞星一号 ",通过带宽利用率提升、并行训练算法优化,讯飞星火在华为 910B 芯片上实现了英伟达 A100 的 90% 的算力能力,而且在部分专用能力领域甚至超越英伟达。
这么一来,讯飞星火大模型 V3.5,一跃成为*全国产算力训练的完全自主知识产权的大模型,不惧 " 卡脖子 " 的风险。
强强联合之下,科大讯飞跻身大模型的*梯队。
关于此,从刚刚结束不久的第 27 届联合国科技大会就可见一斑:科大讯飞与 OpenAI、谷歌、微软等数十家国内外知名企业共同参与、编制《生成式人工智能应用安全测试标准》和《大语言模型安全测试方法》两项国际标准,其中科大讯飞深度参与制定《生成式人工智能应用安全测试标准》,彰显了其人工智能技术实力与国际影响力。
总而言之,科大讯飞的立足于大模型算力底座,与国际*先进的能力看齐,从而孵化出长文本、长图文与长语音大模型,凭借文字处理更专业、应用场景更丰富、用户需求更易满足,一举奠定了其大模型的领先地位。
那么,科大讯飞的 " 星火 " 正在 " 燎原 "。
会员:高阳一
免责声明:本文章由会员“高阳一”发布,如果文章侵权,请联系我们处理,本站仅提供信息存储空间服务如因作品内容、版权和其他问题请与本站联系



评论区





